Serialisation is the process of creating a linear stream of bytes or characters corresponding to an object structure (a graph), so the same structure can be re-constructed by de-serialising the stream. This technique is used both to save an object structure to file and to transmit it across a network.
Introduction
Persistence is the term used for storing (application) state in between sessions, in our case model instances represented by objects structures (graphs), and covers file and database storage, including SQL, object and NoSQL databases. The logic of files and databases are so different that it is easier to treat them separately. A file is essentially a sequence or array of bytes, which often encode characters, and serialisation is the term used for generating this byte (or character) sequence from an object structure. The opposite process, de-serialisation, is the process of reconstructing the object structure from the byte stream.
The Resource
EMF uses a(n instance of the) Resource (class) as the container of the object graph and scope of serialisation. The object graph will mainly consist of EObjects, since this is the base superclass of all modelled data, hence we'll use EObjects as a synonym for graph of instances of an Ecore model. Thus, you serialise the EObjects contained in a Resource to an OutputStream (e.g. a FileOutputStream) with its save method, and de-serialise from an InputStream (e.g. a ByteArrayInputStream) into a Resource with its load method, which then will contain the re-constructed EObjects. The Resource class is abstract, and it's the Resource subclass you use that implements the serialisation logic which determines the format of the byte or character sequence. E.g. the XMIResource class supports a generic format named XML Metadata Interchange (XMI), which is an XML-based model format standardised by the Object Management Group (OMG), so if you want your EObjects serialised as XMI, you use an XMIResource as the container. You can implement your own custom format by making your own Resource subclass, e.g. to support existing legacy formats or a format designed to be easier to read and write for humans (e.g. a DSL). The (structure of) EObjects within a Resource is often self-contained, but cross-links between Resources, are supported, and this must be handled by the serialisation and de-serialisation mechanism. EMF uses a dual technique based on URIs: 1) a URI is used to identify a Resource , e.g. "file:/Users/hal/resource2.xmi" and 2) a fragment is used to identify an EObject within a Resource. The fragment is computed by the target Resource's getURIFragment(EObject) method and is typically a path-like string like "/orgUnits/0/workers/2". Together this gives URIs like "file:/Users/hal/resource2.xmi#/orgUnits/0/workers/2" where "#" is used as separator according to the URI standard. The fragment is useful on its own, as it can be used to serialise links within a Resource, too. So, when serialising (saving) a link to a target EObject, a URI to this EObject is created as described above, and the resulting string is used. When de-serialising (loading) a Resource with a cross-link, the URI is split into a base URI and a fragment, and the base URI is used to identify and auto-load the target Resource, before looking up the target EObject by giving the fragment to the Resource's getEObject(String) method. |
Det circles in Resource 1 and 2 are instances of subclasses of EObject, where the classes typically are generated from your Ecore model. The arrows from circles in Resource 1 to Resource 2 are cross-links. From http://www.informit.com/articles/article.aspx?p=1323360&seqNum=5 |
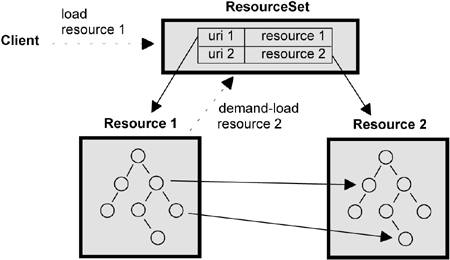
The ResourceSet
As described above, when loading a Resource, you may need to load other Resources as you encounter cross-links. To avoid loading a Resource more than once, it needs to be stored and reused if its URI is encountered later. A ResourceSet is used as the container for Resources, giving a hierarchy of (at least) three levels: a ResourceSet, Resources and EObjects, where each Resource contains part of a large EObject graph, as shown in the figure above. Before loading a Resource, you must add it to a ResourceSet so it 1) can be used for lookup up Resources by URI later and 2) can store the other Resources that are implicitly auto-loaded in the process. The code may look like this:
ResourceSet resourceSet = new ResourceSetImpl();
Resource resource = new XMIResourceImpl(URI.create("file:/Users/hal/resource2.xmi"));
resourceSet.getResources().add(resource);
resource.load(null); // TODO: catch exceptions
| // create an instance of the default ResourceSet implementation // create an instance of the default XMIResource implementation // add the Resource to the ResourceSet // load using default loading options // now the size of resourceSet.getResources() is >= 1 |
The Resource.Factory
The auto-loading mechanism requires a Resource to (be able to) create other Resources. As described above, the Resource implements the serialisation and de-serialisation logic, so it's crucial that the correct Resource subclass is instantiated. But how does the Resource know which subclass to use?
The actual instantiation of a Resource (subclass) is done by a Resource.Factory, and global and local registries of such objects are used to find the appropriate one to use. The global registry is stored in Resource.Factory.Registry.INSTANCE and the local one is stored in the ResourceSet and retrieved by the getResourceFactoryRegistry method. The lookup and instantiation is encapsulated by the ResourceSet's createResource(URI) method, so we only need to write the following code:
ResourceSet resourceSet = new ResourceSetImpl();
Resource resource = resourceSet.createResource(URI.create("file:/Users/hal/resource2.xmi"));
| // create an instance of the default ResourceSet implementation // use it to create the Resource |
However, first we need to make sure the registry is initialised with the relevant Resource.Factory implementations, so our custom ones are found (whether generated or hand-written):
ResourceSet resourceSet = new ResourceSetImpl();
Resource.Factory.Registry registry = resourceSet.getResourceFactoryRegistry();
registry.getExtensionToFactoryMap().put("org", new OrgResourceFactoryImpl());
| // create an instance of the default ResourceSet implementation // retrieve the Resource.Factory.Registry // map the file extension to our Resource.Factory |
To register our Resource.Factory globally, use Resource.Factory.Registry.INSTANCE instead of retrieving the one in the ResourceSet. Note that if you use genmodel and generate code, and install your EMF project into Eclipse, this is done automatically, using Eclipse's plugin.xml-based extension mechanism. If running standalone, as in an ordinary JUnit test, you must include similar code, in the case of JUnit in the setUp or @BeforeClass method.
The EPackage.Registry
In the code above for loading a Resource, an important element is missing. When de-serialising a model instance, e.g. when creating and linking EObjects, the EClasses of a model is needed and hence the containing EPackage. EMF identifies the latter by its nsURI, so this identifies is typically included in the character stream. E.g. in the XMI format described below, XML namespaces are related to the nsURI. However, this only solves half the problem, the other being retrieving the corresponding EPackage object. For this an EPackage.Registry is used.
An EPackage.Registry is a map from the nsURI to the corresponding EPackage object, and as for Resource.Factory.Registry, there is a global one and local ones the ResourceSets. The global one can be retrieved from EPackage.Registry.INSTANCE and the local ones using ResourceSet's getPackageRegistry() method. To initialise it with a specific EPackage (here OrgPackage), you write code similar to the following:
ResourceSet resourceSet = new ResourceSetImpl(); EPackage.Registry registry = resourceSet.getPackageRegistry(); // or EPackage.Registry.INSTANCE registry.put(OrgPackage.eINSTANCE.getNsURI(), OrgPackage.eINSTANCE); // map from nsURI to EPackage instance |
As for Resource.Factory.Registry, if you use genmodel and generate code, and install your EMF project into Eclipse, this is done automatically, using Eclipse's plugin.xml-based extension mechanism. If running standalone, as in an ordinary JUnit test, you must include similar code, in the case of JUnit in the setUp or @BeforeClass method.
Supported serialisation formats
EMF itself supports both the standardised XMI format and more ad-hoc XML-formats. Other projects supports more human-readable ones.
XMI
The XMI format is based on the hierarchical XML syntax. To support this format, the general structure of an EObject graph must be mapped to the general structure of XML: Ecore has packages, types, attributes, references (including containment) of Ecore, while XML has namespaces, nested elements (tags) and string attributes. The XMI format uses namespaces to identify packages, elements (tags) to identify types and references and string attributes both for simple attributes and references. Consider the example below:
<org:OrgModel xmi:version="2.0"
xmlns:org="platform:/plugin/no.hal.org/model/org.ecore">
<orgUnits>
<workers
name="Hallvard "hal" Trætteberg"
role="//@roles.0"/>
</orgUnits>
<roles
name="manager"/>
</org:OrgModel>
| the root object is of the type org:OrgModel
relates the org prefix to our "org" package's identifying URI
a contained instance that is orgUnits-related to the outer object, implicitly an OrgUnit
a contained instance that is workers-related to the outer object, implicitly a Person
name attribute and value
role reference and link using path-like reference
a contained instance that is roles-related to the outer object, implicitly a Role
name attribute and value
|
Note how only the top-level element refers to an type (EClass), while the other elements refer to EReferences. In general, elements corresponds to the creating of EObjects, so the root element needs an EClass name. The inner elements corresponds to both instance creation and containment, and since the element identifies an EReference both are supported: the EReference's type is an EClass and it represents the containment. So, in the above example, "orgUnit" identifies the orgUnit EReference in OrgModel (the containing EObject's EClass) and implicitly the OrgUnit EClass, which is that EReference's type. If the actual type to instantiate is a subtype of the EReference's type, then a special attribute named "xsi:type" is included, with the EClass name as its value. Here it would have been xsi:type="org:OrgUnit", but it's omitted since it isn't necessary.
XML
EMF support variations of the XMI format, e.g. you can use elements for attribute values, use rename the elements and attributes etc. This is achieved by using an XMLResource and adding EAnnotations to EClasses and EStructuralFeatures for describing the choices concerning serialisation. Although this can be done to make the XML more comfortable to read and write, the usual (and better) reason is to support existing, standardised or legacy formats, so they can be consumed by EMF without having to hand-write your own Resource subclass. The easiest way to do this is to start with an XML schema (xsd file) and generate an Ecore from it using the genmodel wizard. This will give you an Ecore model with appropriate EAnnotations, so instances of that Ecore model can be saved/loaded to/from the format described by the XML schema. See this tutorial for details.
JSON
XML is becoming an old format and nowadays is JSON replacing it everywhere, both as a storage format (file and database) and for network communication. Several projects support JSON-based serialisation, and the EMFJSON project provides a ready-to-use Resource subclass and many ways of customising the format. The general structure is similar to the XMI format, with the same nesting and use of attributes for both EAttributes and EReferences.
JSON-like
The ESON project supports a generic JSON-like syntax, that is even easier to use than JSON, but note it's not proper JSON.
The Human-Usable Textual Notation (HUTN) is a standardised syntax for a JSON like syntax for models instances, and is supported by the Epsilon project.
Custom
The Xtext and EMFText frameworks supports defining custom syntaxes for your data using a grammar from which a serialiser and de-serialiser (parser) will be generated.