Serialisation is the process of creating a linear stream of bytes or characters corresponding to an object structure (a graph), so the same structure can be re-constructed by de-serialising the stream. This technique is used both to save the object structure to file and to transmit it across a network.
Introduction
Persistence is the term used for storing (application) state in between sessions, in our case model instances represented by objects structures (graphs), and covers file and database storage, including SQL, object and NoSQL databases. The logic of files and databases are so different that it is easier to treat them separately. A file is essentially a sequence or array of bytes, which often encode characters, and serialisation is the term used for generating this byte (or character) sequence from an object structure. The opposite process, de-serialisation, is the process of reconstructing the object structure from the byte stream.
The Resource and ResourceSet classes
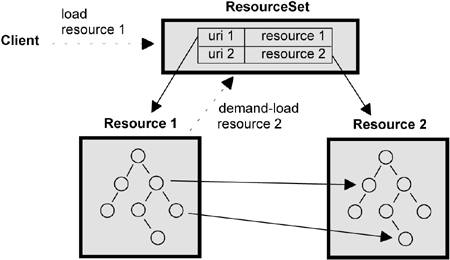
EMF uses a(n instance of the) Resource (class) as the container of the object graph and scope of serialisation. The object graph will mainly consist of EObjects, since this is the base superclass of all modelled data, hence we'll use EObjects as a synonym for graph of instances of an Ecore model. if You serialise the EObjects contained in a Resource to an OutputStream (e.g. a FileOutputStream) with its save method, and de-serialise from an InputStream (e.g. a ByteArrayInputStream) into a Resource with its load method, which will contain the re-constructed object structure. The Resource class is abstract, and it's the Resource subclass you use that implements the serialisation logic which determines the format of the byte sequence. E.g. the XMIResource class supports a generic format named XML Metadata Interchange (XMI), which is an XML-based model format standardised by the Object Management Group (OMG), so if you want your EObjects serialised as XMI, you use an XMIResource as the container of your EObjects. You can implement your own custom format by making your own Resource subclass, e.g. to load existing legacy formats or a format designed to be easier to read and write for humans (e.g. a DSL). The (structure of) EObjects within a Resource is often self-contained, but cross-links between Resources, are supported, and this must be handled by the serialisation and de-serialisation mechanism. EMF uses a dual technique based on URIs: 1) a URI is used to identify a Resource , e.g. "file:/Users/hal/resource2.xmi" and 2) a fragment is used to identify an EObject within a Resource. The fragment is typically a path-like string like "/orgUnits/0/workers/2", and can be used alone to serialise links within a Resource. Together this gives URIs like "file:/Users/hal/resource2.xmi#/orgUnits/0/workers/2" where "#" is used as separator according to the URI standard. A Resource is identified by a URI, which typically matches the source of the byte stream from which it was loaded, e.g. a URL or filesystem path. The URI is important for supporting so-called cross-links, which is when an EObject in one Resource refers to an EObject in another Resource (illustrated in the figure to the right). When serialising such links, the first Resource, must encode a reference to the EObject in the other Resource. The URI will be used to refer to the Resource, and then a reference to the EObject within the Resource is appended as the URI's so-called fragment, giving something like "file:/Users/hal/resource2.xmi#/path/to/object". The fragment is the part after the #, and the actual format of the fragment is decided by the target Resource's getURIFragment method (which has a default implementation which can be overridden). When loading a Resource with a cross-link, the object reference is resolved and the target Resource is loaded, too, so in practice you may end up with many Resources, each containing part of a large object graph. To have a place to put all these Resources, you use a ResourceSet, as shown in the figure. Summarised: A ResourceSet contains a set of linked Resources and a Resource contains an object structure. A Resource is identified by a URI and objects within a Resource by a URI with a fragment. |
Det circles in Resource 1 and 2 are instances of subclasses of EObject, where the classes typically are generated from your Ecore model. The arrows from circles in Resource 1 to Resource 2 are cross-links. From http://www.informit.com/articles/article.aspx?p=1323360&seqNum=5 |
The Resource.Factory class
Since a Resource implements important logic for handling serialisation, it is important to use the right subclass as a container for your model instance, to ensure the correct format is used. Although you may use several format, e.g. XMI for file storage and JSON for REST, the format and hence Resource subclass is usually the same for all instances of a model.
The XMI format
As mention above, EMF has support for the XMI format, which is based on the hierarchical XML syntax.
<org:OrgModel xmi:version="2.0"
xmlns:org="http://plugin/no.hal.org/model/org.ecore"
xsi:schemaLocation="http://plugin/no.hal.org/model/org.ecore file:/Users/hal/java/workspaces/tdt4250/no.hal.org/model/org.ecore">
<orgUnits>
<workers
name="Hallvard "hal" Trætteberg"
role="//@roles.0"/>
</orgUnits>
<roles
name="manager"/>
</org:OrgModel>
| identifies the root object as being of the type org:OrgModel |
Model instances are graphs in general, but it is easier to think of them as mostly hierarchical, with links across. Hence, a serialisation mechanism will typically need to support the following features:
- type information, i.e. references to EClasses in the model, so instances can be created
- attribute values, corresponding to EAttributes, so attributes of instances can be set or filled
- links, corresponding to EReferences, similar to attributes where the values are strings that can resolve to objects in the context of the object hierarchy
- containment, corresponds to EReference with containment flag set
Given these features, it is pretty easy to make a general algorithm for serialising and de-serialising object structures. To serialise, identify the root object(s) and traverse the object hierarchy. For each object output the EClass reference, and for each EStructuralFeature, output the name and values (for EAttributes) or resolvable object references (for EReferences). For containment, use some kind of nesting indicator, like curly braces and/or indentation, combined with the name of the containment EReference's name. To de-serialise, create the objects and set or fill the attributes while parsing, and store the EReference names and object identities. Containment can also handles during parsing, based on the nesting and EReference names. After the object hierarchy has been created, link them together by resolving the object references and setting or filling the EReferences.