T-test i par
...
– begreper
T-fordelingen
T-fordelingen brukes i stedet for z-fordelingen dersom standardavviket er ukjent. Fordelingen gir bredere konfidensintervaller enn normalfordelingen og større sannsynlighet for å få observasjoner langt unna den sanne forventningen. Fordelingen vil nærme seg normalfordelingen dersom n øker.(Se figur 1)
Ved bruk av t-fordelingen brukes oftest kvantilene, α. Hvis en har en t-fordelt variabel, med k frihetsgrader, kan en slå opp i t-fordelingstabellen og finne hvilken t-verdi det er for eksempel 20 % (α=0,20) sannsynlighet for at T vil befinne seg over. P(T> tα)= α
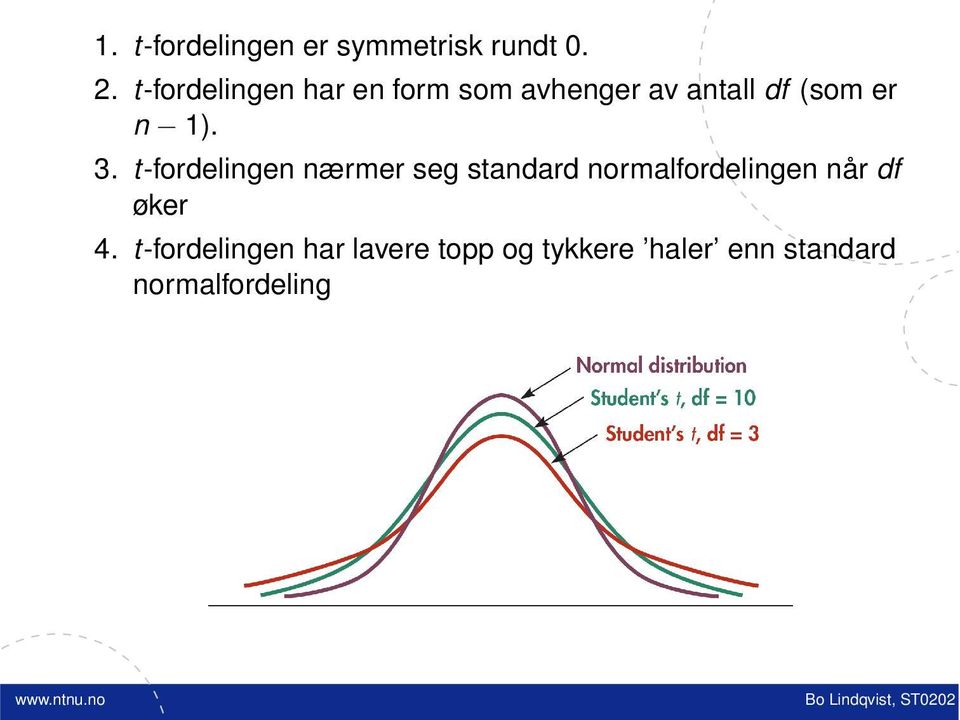
Figur 1: t-fordelingen nærmer seg normalfordelingen
Estimering av t
I mange praktiske situasjoner er en populasjons sanne standardavvik ukjent, fordi det er få observasjoner i forsøket. Estimering av t baseres på estimert standardavvik.
T-test
En t-test (også kalt Students t-test) er en statistisk hypotesetest basert på Students t-fordeling.
To utvalg
Dersom en har to grupper av data kan en bruke t-test med to utvalg. Testen blir mest pålitelig dersom gruppene pares mot hverandre i en paret t-test. Dette er ikke alltid mulig og da kan man bruke uparet t-test.
Frihetsgrader
er tallet du bruker i t-test fordelings tabeller, frihetsgrader er n-1 der n er antall utførelser for å få et gjennomsnitt.
Alfa
er 1-sannsynlighet. skal sikkerheten på svaret være på 95% vil alfa være 1 - 0.95. og en bruker ofte alfa halve, så en deler alfa på 2.
Uparet t-test
Brukes når de to datasettene kommer fra to forskjellige utvalg. Også kalt uavhengige utvalgs/gruppers t-test.
Teori
Paret t-test
Brukes når en skal finne ut om det er signifikant forskjell i gjennomsnittet av to datasett. et eksempel på to datasettene kan være mellom to målemetoder/analyser av samme stoff/prøver.
eksempel 1:
Et eksempel kan være å undersøke forskjellen i slitasje på to ulike sko, der n personer deltar og prøver ut to to ulike skoene. I dette eksempelet vil nullhypotesen være at skoene slites like mye, og H1-hypotesten påstår at de to skoene har ulik slitasje.
H0: Lik slitasje μ1 = μ2
H1: Ulik slitasjeμ1 ≠ μ2
μ1og μ2 står for de ulike gruppegjennomsnittene. En har n ulike X-verdier i gruppe 1, og tilsvarende Y-verdier i gruppe 2. En kan utføre forsøket ved å utstyre syv personer med de to ulike skotyper som skal undersøkes. Så vil X-verdiene være antall millimeter skotype 1 slites og Y-verdiene være antall millimeter skotype 2 slites. I utregningen av testobservatoren brukes differansen av middelverdiene i gruppe 1 og 2., Som estimator på standardavviket S, regner en ut standardavvikene innad gruppene, dette kan gjøres på excel eller kalkulator ved å sette inn data.
Tabell 1: Skoforsøk med n=7
...