...
Persistence is the term used for storing (application) state in between sessions, in our case model instances represented by objects structures (graphs), and covers file and database storage, including SQL, object and NoSQL databases. The logic of files and databases are so different that it is easier to treat them separately. A file is essentially a sequence or array of bytes, which often encode characters, and serialisation is the term used for generating this byte (or character) sequence from an object structure. The opposite process, de-serialisation, is the process of reconstructing the object structure from the byte stream.
...
The Resource
EMF uses a(n instance of the) Resource (class) as the container of the object graph and scope of serialisation. The object graph will mainly consist of EObjects, since this is the base superclass of all modelled data, hence we'll use EObjects as a synonym for graph of instances of an Ecore model. Thus, you serialise the EObjects contained in a Resource to an OutputStream (e.g. a FileOutputStream) with its save method, and de-serialise from an InputStream (e.g. a ByteArrayInputStream) into a Resource with its load method, which then will contain the re-constructed EObjects. The Resource class is abstract, and it's the Resource subclass you use that implements the serialisation logic which determines the format of the byte or character sequence. E.g. the XMIResource class supports a generic format named XML Metadata Interchange (XMI), which is an XML-based model format standardised by the Object Management Group (OMG), so if you want your EObjects serialised as XMI, you use an XMIResource as the container. You can implement your own custom format by making your own Resource subclass, e.g. to support existing legacy formats or a format designed to be easier to read and write for humans (e.g. a DSL). The (structure of) EObjects within a Resource is often self-contained, but cross-links between Resources, are supported, and this must be handled by the serialisation and de-serialisation mechanism. EMF uses a dual technique based on URIs: 1) a URI is used to identify a Resource , e.g. "file:/Users/hal/resource2.xmi" and 2) a fragment is used to identify an EObject within a Resource. The fragment is computed by the target Resource's getURIFragment(EObject) method and is typically a path-like string like "/orgUnits/0/workers/2". Together this gives URIs URIs like "file:/Users/hal/resource2.xmi#xmi#/orgUnits/0/workers/2" where "#" is used as separator according to the URI standard. The fragment is useful on its own, as it can be used to serialise links within a Resource, too. So, when serialising (saving) a link to a target EObject, a URI to this EObject is created as described above, and the resulting string is used. When de-serialising (loading) a Resource with a cross-link, the URI is split into a base URI is resolved and and a fragment, and the base URI is used to identify and auto-load the target Resource loaded, before looking up the target EObject using its by giving the fragment to the Resource's getEObject(String) method. |
Det circles in Resource 1 and 2 are instances of subclasses of EObject, where the classes typically are generated from your Ecore model. The arrows from circles in Resource 1 to Resource 2 are cross-links. From http://www.informit.com/articles/article.aspx?p=1323360&seqNum=5 |
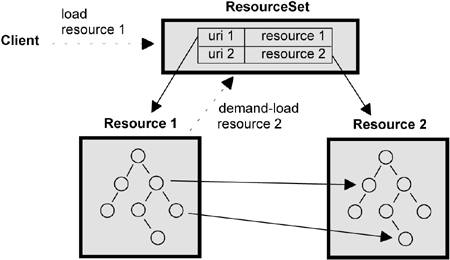
ResourceSets
so in practice you may end up with many Resources, each containing part of a large object graph. To have a place to put all these Resources, you use a ResourceSet, as shown in the figure.
Summarised: A ResourceSet contains a set of linked Resources and a Resource contains an object structure. A Resource is identified by a URI and objects within a Resource by a URI with a fragment.
The Resource.Factory class
The ResourceSet
As described above, when loading a Resource, you may need to load other Resources as you encounter cross-links. To avoid loading a Resource more than once, it needs to be stored and reused if its URI is encountered later. A ResourceSet is used as the container for Resources, giving a hierarchy of (at least) three levels: ResourceSet, Resource and EObjects, where each Resource contains part of a large EObject graph, as shown in the figure above. Before loading a Resource, you must add it to a ResourceSet so it 1) can be used for lookup up Resources by URI later and 2) can store the other Resources that are implicitly auto-loaded in the process. The code may look like this:
|
|
The Resource.Factory
The auto-loading mechanism requires a Resource to (be able to) create other Resources. As described above, the Resource implements the serialisation and de-serialisation logic, so it's crucial that the correct Resource subclass is instantiated. But how does the Resource know which? The actual instantiation is done by a Resource.Factory, and global and local registries of such objects are used to find the appropriate one to use. The global registry is stored in Resource.Factory.Registry.INSTANCE and the local one is stored in the ResourceSet containing the Resource and retrieved by the getResourceFactoryRegistry method. The lookup for the Resource.Factory is done on the URI of the to-be-created Resource, and since the local one delegates to the global one, the following code could be used to create it:
|
|
that is used to find ResourceSet-local (in the containing ResourceSet) map Since Since a Resource implements important logic for handling serialisation, it is important to use the right subclass as a container for your model instance, to ensure the correct format is used. Although you may use several format, e.g. XMI for file storage and JSON for REST, the format and hence Resource subclass is usually the same for all instances of a model.
...